Tech Sector Shaken: Google’s New Efficiency Tech Erases $450B in Value as Memory Prices Tank.
One blog post. One algorithm. Four hundred and fifty billion dollars erased.
On March 25, 2026, Google published details of a new compression technique called TurboQuant. Within 48 hours, the global memory semiconductor market was in freefall. Major chipmakers watched their valuations collapse. Investors hit the sell button hard and fast.
According to CNBC, Google’s TurboQuant can reduce the memory required to run large language models by up to six times. That single claim was enough to send shockwaves through one of the world’s most capital-intensive industries.
However, the full picture is considerably more nuanced than the headlines suggest. This article breaks down exactly what TurboQuant is, what the market reaction actually tells us, and what investors and technology professionals need to understand about where this story goes next.
What Is Google TurboQuant? A Technical Breakdown
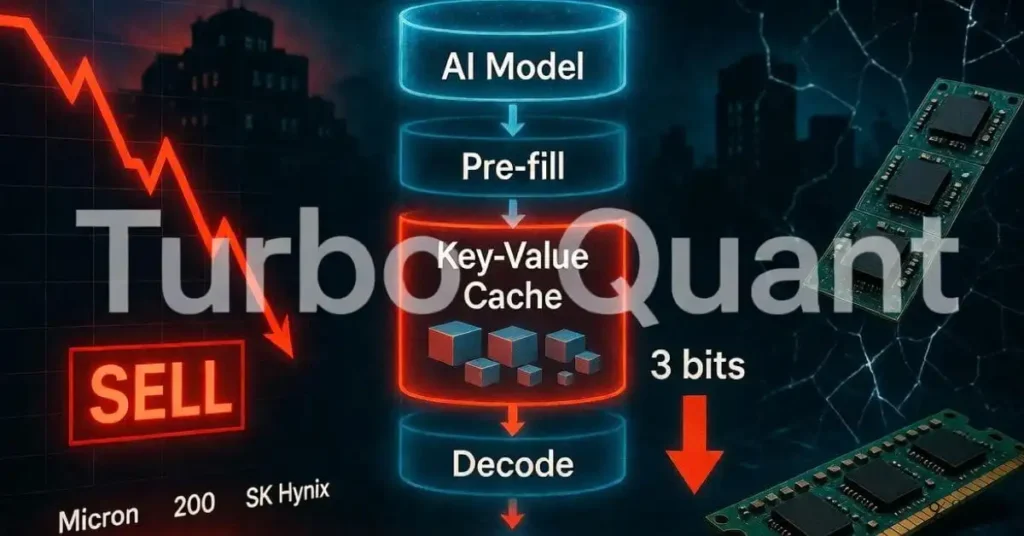
TurboQuant is an advanced quantisation algorithm developed by Google. Its primary function is to compress the data that large language models process during inference. Specifically, it targets the key-value cache, which is the component of an AI model that stores past calculations so they do not need to be repeated.
According to TechPowerUp, TurboQuant achieves this efficiency through two novel techniques working together. The first is PolarQuant, which simplifies data geometry using polar coordinates to eliminate traditional memory overhead. The second is Quantised Johnson-Lindenstrauss, or QJL, a 1-bit mathematical error-checking method.
Together, these two approaches allow TurboQuant to compress the key-value cache to just 3 bits. That is an extraordinary level of compression. For context, most AI inference today operates at 16-bit or 8-bit precision. Dropping to 3 bits without sacrificing meaningful model accuracy represents a genuine engineering achievement.
Furthermore, TechPowerUp reports that TurboQuant enables up to 8x faster runtimes on GPUs and requires no fine-tuning of the underlying model. That last point matters enormously. Fine-tuning is expensive and time-consuming. A compression method that simply drops into an existing pipeline without retraining costs is immediately deployable.
The Key-Value Cache: Why It Matters
To understand why TurboQuant is significant, you need to understand the key-value cache. When a large language model processes a long conversation or document, it performs calculations at every step. Without caching, it would repeat those calculations from scratch each time a new token is generated. That is enormously wasteful.
The key-value cache stores the results of those earlier calculations. It allows the model to reference previous context without reprocessing it. However, the cache grows with the length of the context window. For a 70-billion-parameter model serving many users with long contexts, the cache can consume the majority of available GPU memory.
This memory bottleneck is one of the most significant constraints on AI inference efficiency today. It limits how many users a single GPU can serve simultaneously and drives up the cost per interaction. TurboQuant directly attacks this bottleneck by making the cache dramatically smaller.
The Market Reaction: Billions Wiped Out in Days
The financial fallout from the TurboQuant announcement was swift and brutal. Memory semiconductor stocks fell sharply across the board.
According to Decoding Discontinuity’s analysis, Micron fell 30% since its March 18 earnings report. SK Hynix dropped 6.2% in a single trading session. SanDisk, a NAND flash storage company with no direct connection to inference-time cache compression, shed 18% in five days. Even Nvidia, whose Blackwell architecture is specifically optimised for low-precision computation of exactly the kind TurboQuant enables, fell 6.6%.
The scale of the sell-off surprised many analysts. A blog post about a compression algorithm triggering a $450 billion market capitalisation loss is an extraordinary event. It speaks to how sensitive investors have become to any news that might reduce AI infrastructure spending.
Why Investors Responded So Dramatically
The AI memory boom has been one of the biggest investment themes of the past three years. Demand for high-bandwidth memory, or HBM, has been explosive. Micron and SK Hynix have been among the biggest beneficiaries. Their stocks had run up substantially heading into early 2026.
According to CNBC, Ben Barringer, head of technology research at Quilter Cheviot, offered a measured view: ‘Memory stocks have had a very strong run, and this is a highly cyclical sector, so investors were already looking for reasons to take profit.’
Barringer added that the TurboQuant innovation added to the pressure, but described it as evolutionary rather than revolutionary. His view is that it does not alter the long-term demand picture for the industry. In a market primed to de-risk, even an incremental development can serve as a cue to reduce exposure.
This context is important. The TurboQuant announcement was not the sole cause of the sell-off. Rather, it was a catalyst that released tension that had been building in overextended positions. The fundamental question is whether the market’s reaction was proportionate to the actual technological impact.
Table 1: Memory Semiconductor Stock Price Impact Following TurboQuant Announcement
| Company | Sector | Price Drop | Direct Connection to TurboQuant? |
| Micron | DRAM / HBM | -30% (from Mar 18) | Yes (KV cache memory) |
| SK Hynix | DRAM / HBM | -6.2% (single session) | Yes (KV cache memory) |
| SanDisk | NAND Flash Storage | -18% (five days) | No (NAND is unrelated) |
| Nvidia | GPU / AI Accelerators | -6.6% | Indirect (optimised for low-precision) |
The Technical Reality: What TurboQuant Actually Does and Does Not Do
Much of the market panic rested on a misunderstanding. TurboQuant is a powerful and genuinely important advancement. However, it is a narrow one. Its scope is limited to a specific layer of the AI stack, and investors who treated it as a wholesale reduction in AI memory demand were not reading the technical details carefully.
According to Decoding Discontinuity, TurboQuant is strictly an inference economy technology. It operates exclusively at the inference layer. It provides zero benefit to model training. It does not compress model weights, training data, or storage. The algorithm compresses only the inference-time key-value cache.
This distinction is critical. Training large AI models consumes enormous quantities of memory and compute. That demand is not touched by TurboQuant at all. SanDisk’s NAND flash products have almost nothing to do with inference-time cache compression. The 18% drop in SanDisk shares was almost entirely sentiment-driven panic rather than fundamental analysis.
What TurboQuant Changes at the Inference Layer
At the inference layer, TurboQuant’s impact is real and substantial. Decoding Discontinuity explains the practical implications with a concrete example.
Before TurboQuant, serving a 70-billion-parameter model to 512 concurrent users with 128,000-token contexts required a multi-node GPU cluster. Costs ran between $50,000 and $100,000 per month. The key-value cache alone consumed most of the available GPU memory, limiting concurrency to a handful of sessions per GPU.
After TurboQuant, that same workload could potentially fit on two H100 GPUs. The cache shrinks dramatically. The number of concurrent sessions per GPU expands. The cost per session collapses. For companies building AI products at scale, this is a very significant efficiency gain.
Table 2: Inference Workload Comparison Before and After TurboQuant (70B Parameter Model, 512 Users, 128K Context)
| Metric | Before TurboQuant | After TurboQuant |
| Hardware required | Multi-node GPU cluster | Approximately 2 x H100 |
| Estimated monthly cost | $50,000 to $100,000 | Significantly reduced |
| KV cache size | Full precision (16-bit) | 3-bit (compressed) |
| Concurrent sessions per GPU | Very limited | Substantially expanded |
| Model accuracy loss | N/A (baseline) | Minimal (error-corrected) |
Is the Sell-Off Justified? The Bull Case for Memory
Panic selling is rarely rational. The TurboQuant-driven sell-off, while dramatic, may represent an overreaction that creates opportunity rather than a genuine structural shift in memory demand. Several credible arguments support a more optimistic view.
According to Tech Research Online, investors who track global memory stocks hold a different view from the panicked sellers. They argue that better efficiency will likely boost memory demand rather than reduce it. The reasoning is straightforward: lower cost per token drives wider product adoption, which in turn drives higher total compute consumption.
Morgan Stanley analyst Shawn Kim echoed this view, stating that lower cost per token could result in higher product adoption, which ultimately benefits memory chip producers in the long run. This is the classic Jevons Paradox applied to AI infrastructure. Efficiency gains historically increase total consumption rather than reduce it by making the technology accessible to more users and use cases.
The Jevons Paradox in AI Infrastructure
The Jevons Paradox was first observed in the 19th century when more efficient steam engines led to more coal consumption, not less. The principle applies directly here. When AI inference becomes cheaper, more developers build AI-powered products. More products attract more users. More users generate more inference requests.
Even if each inference requires less memory due to TurboQuant, the total number of inferences could grow fast enough to offset and exceed that efficiency gain. This pattern has played out repeatedly across computing history. Cheaper storage led to more data generation. Faster processors enabled heavier software. Efficient networking drove exponential traffic growth.
Therefore, the assumption that TurboQuant reduces total memory demand is far from certain. The more likely outcome, given how much latent demand exists for affordable AI at scale, is that it accelerates the market rather than constraining it.
The Agentic Era: Why Long-Context Inference Efficiency Matters Now
TurboQuant’s timing is not accidental. It arrives precisely as the AI industry is transitioning from simple single-turn chat applications to complex multi-step agentic workflows. This shift changes the calculus around memory consumption dramatically.
Agentic AI systems do not just answer a single question. They plan, research, reason across many steps, use tools, and maintain context across extended interactions. A coding agent might read an entire codebase. A research agent might synthesise hundreds of documents. A customer service agent might maintain context across a month-long ticket history.
Each of these use cases requires a long context window. Long context windows generate enormous key-value caches. Before TurboQuant, serving these workloads economically at scale was a genuine challenge. As Decoding Discontinuity explains, TurboQuant’s entire value proposition is to make long-context LLM inference economically viable at scale.
Consequently, TurboQuant is not a threat to the AI infrastructure buildout. It is an enabler of the next phase of it. The applications that will drive the next wave of AI adoption are precisely the ones that benefit most from more efficient long-context inference.
Table 3: What TurboQuant Affects vs. What It Does Not Affect
| AI Stack Layer | TurboQuant Impact | Memory Demand Implication |
| Inference (KV cache) | Direct and significant | Reduced per-session need |
| Model training | None (zero benefit) | Unchanged |
| Model weights storage | None | Unchanged |
| Training data storage | None | Unchanged |
| NAND flash storage | None | Unchanged |
| Long-context agentic use | Enables wider deployment | Likely to increase total demand |
How TurboQuant Fits Into Google’s Broader Strategy
TurboQuant does not exist in isolation. It is part of a broader push by Google to maintain a competitive advantage in the AI infrastructure race. Efficiency innovations like this serve multiple strategic purposes simultaneously.
First, they reduce Google’s own operational costs for running Gemini and other AI services at a massive scale. Google processes billions of AI queries daily. Even a modest reduction in memory cost per query translates to enormous savings across that volume.
Second, publishing the research openly signals technical leadership. By demonstrating that Google can compress KV caches to 3 bits with minimal accuracy loss, the company reinforces its position at the frontier of AI efficiency research. This matters for talent acquisition, developer ecosystem trust, and competitive positioning.
Third, the technology enables new product capabilities. CNBC notes that making AI models more efficient is a major goal of all leading labs. Making long-context inference cheap enough to serve at consumer scale opens up product opportunities that were previously cost-prohibitive.
The Competitive Landscape After TurboQuant
Google is not the only company working on inference efficiency. OpenAI, Anthropic, Meta, and a growing ecosystem of AI infrastructure startups are all pursuing similar goals. TurboQuant raises the bar for the entire industry.
Competitors will need to match or exceed this efficiency level to remain cost-competitive. This intensifies the engineering race around quantisation, caching, and inference optimisation more broadly. The companies that solve these problems fastest gain durable cost advantages in AI product delivery.
Moreover, the hardware ecosystem must adapt. NVIDIA’s Blackwell architecture is already optimised for low-precision computation, as Decoding Discontinuity points out. Future GPU and AI accelerator designs will likely incorporate hardware-level support for the specific precision levels that algorithms like TurboQuant target. This creates a virtuous cycle between software efficiency and hardware optimisation.
Implications for the Global Semiconductor Industry
The TurboQuant sell-off raises legitimate questions about how semiconductor investors should think about AI-driven demand going forward. The reflexive assumption that any efficiency gain is bad for chip demand deserves scrutiny.
Memory chips for AI applications are not a single monolithic market. High-bandwidth memory for training and inference accelerators, DRAM for CPU-based workloads, NAND flash for storage, and specialised AI memory formats all serve different parts of the stack. TurboQuant’s impact on each of these categories varies enormously.
The training computer market is untouched by TurboQuant. The buildout of data centres for model training continues at pace. The largest AI labs are still ordering GPU clusters at scale. That demand pipeline does not change because of a more efficient inference cache.
Additionally, Tech Research Online reports that analysts view TurboQuant as beneficial for hyperscalers due to its ability to improve returns on investment. Hyperscalers are the largest buyers of AI infrastructure globally. If TurboQuant improves its ROI on AI deployments, it could actually accelerate its infrastructure spending rather than slow it.
Table 4: TurboQuant Impact Assessment by Memory Market Segment
| Memory Segment | Key Players | TurboQuant Impact | Demand Outlook |
| HBM (AI training) | SK Hynix, Micron, Samsung | Minimal direct impact | Still strong |
| DRAM (inference) | Micron, SK Hynix | Moderate (KV cache reduction) | Mixed near-term |
| NAND Flash | SanDisk, Samsung, Kioxia | None | Unaffected (panic selling) |
| GPU Memory (GDDR7) | Micron, Samsung | Indirect (more sessions/GPU) | Potentially positive long-term |
What This Means for AI Infrastructure Investors
The TurboQuant event is a useful case study in how markets respond to AI technology news. It illustrates several patterns that investors in AI infrastructure need to understand going forward.
First, the market is hypersensitive to efficiency narratives. Any credible announcement that AI could do more with less hardware triggers a disproportionate sell-off. This sensitivity reflects how much of the AI-era premium in chip stocks is based on an assumption of relentlessly growing memory demand. When that assumption is challenged, even partially, the repricing can be severe.
Second, narrative speed outpaces analysis speed. The sell-off happened within 48 hours of the announcement. That is not enough time for most institutional investors to read the technical paper carefully, model the actual demand implications, and make calibrated decisions. Panic sells into falling prices. Considered analysis comes later.
Third, the long-term thesis for AI memory demand remains intact. CNBC’s reporting reflects the consensus view that TurboQuant is evolutionary rather than revolutionary. It does not alter the fundamental trajectory of AI adoption or the infrastructure required to support it.
Key Questions for Investors Going Forward
Several questions will shape how this story develops over the coming months. Will other AI labs quickly adopt TurboQuant or equivalent techniques? Will the efficiency gains actually translate into lower memory purchasing, or will they be absorbed by expanded AI deployment at scale? How will hardware vendors respond to the new precision requirements?
Additionally, how quickly does the market reprice after the initial panic? Historical patterns in semiconductor cycles suggest that sentiment-driven sell-offs in fundamentally sound businesses tend to recover when earnings data proves the fundamental demand case intact. The memory market’s next earnings cycle will be closely watched for evidence of real demand changes.
The Broader Lesson: Efficiency and Scale Are Not Opposites
The TurboQuant story ultimately illustrates a misunderstanding that keeps recurring in technology investing. Efficiency gains are routinely interpreted as demand destroyers when history consistently shows they are demand accelerators.
Better compression makes AI cheaper. Cheaper AI reaches more users and more use cases. More use cases require more total compute, even if each computation requires less memory than before. The market that exists for AI applications at today’s cost is a fraction of the market that exists at half the cost.
This dynamic played out with hard disk drives, with cloud storage, with mobile data, and with virtually every other compute-adjacent technology. Each time a meaningful efficiency breakthrough occurred, the bear case predicted demand destruction. Each time, the actual outcome was market expansion.
Furthermore, TurboQuant specifically targets the bottleneck that is currently limiting agentic AI deployment at scale. Removing that bottleneck does not reduce the market for AI infrastructure. It opens a new phase of growth that the previous bottleneck was preventing.
The $450 billion market blow was a real event. The valuations that were erased in those 48 hours represent genuine capital destruction for investors who sold into the panic. However, for those who understand the underlying technology and the historical patterns of efficiency-driven market expansion, the sell-off likely presented an opportunity rather than a warning.
Table 5: TurboQuant Event Summary for Technology Investors
| Factor | Bear View | Bull View |
| KV cache compression | Less memory needed per session | More sessions are deployed at a lower cost |
| Training demand | Unchanged concern | Completely unaffected by TurboQuant |
| Agentic AI growth | Offset by efficiency | TurboQuant enables the next wave |
| Hyperscaler ROI | Lower spending per AI task | Better ROI accelerates deployment |
| Long-term memory demand | Structurally lower | Likely higher via Jevons Paradox |
Final Thoughts: Reading the Signal Through the Noise
Google TurboQuant is a genuine technical achievement. Compressing the KV cache to 3 bits with minimal accuracy loss, enabling 8x faster GPU runtimes, and requiring no model fine-tuning is impressive engineering. It addresses a real bottleneck in AI inference economics and will likely accelerate the deployment of agentic AI applications.
The market reaction, however, overshot the actual implications by a considerable margin. Selling NAND flash companies because of a KV cache compression algorithm, or treating a training-neutral efficiency gain as a wholesale threat to memory demand, reflects panic rather than analysis.
As Decoding Discontinuity concluded, the sell-off conflated a narrow efficiency gain at one layer of the AI stack with a structural reduction in demand across the entire stack. That conflation is the story, not the technology itself.
The real story is this: AI is getting cheaper, faster, and more powerful all at once. That combination does not destroy demand for the infrastructure that makes it possible. If history is any guide, it creates far more demand than it eliminates.
Watch the next earnings cycle from Micron and SK Hynix closely. The data will tell a more honest story than the headlines did.
Spend some time on your future.
To deepen your understanding of today’s evolving financial landscape, we recommend exploring the following articles:
War Economy Chapter 16: Currency Devaluation During War
Retirement Calculator Formula: How to Estimate Your Future Needs
The Diversification Myth: Understanding Correlation Breakdown During Market Stress
The Startup GTM Playbook: Launching Your Product to the Right Audience
Explore these articles to get a grasp on the new changes in the financial world.
Disclaimer
This article is for informational and educational purposes only. Nothing in this article constitutes financial or investment advice. All market data and statistics referenced reflect information available at the time of writing and are subject to change. Always conduct your own research and consult a qualified financial advisor before making investment decisions. Past market performance does not predict future outcomes.
References
[1] CNBC, ‘A Google AI Breakthrough is Pressuring Memory Chip Stocks,’ March 26, 2026. [Online]. Available: https://www.cnbc.com/2026/03/26/google-ai-turboquant-memory-chip-stocks-samsung-micron.html. [Accessed: Mar. 2026].
[2] Tech Research Online, ‘Google TurboQuant Triggers Global Memory Stock Selloff,’ March 26, 2026. [Online]. Available: https://techresearchonline.com/news/google-turboquant-memory-stock-selloff/. [Accessed: Mar. 2026].
[3] Decoding Discontinuity, ‘TurboQuant and the Memory Stock Sell-Off: Why the Panic Outpaced the Paper,’ March 31, 2026. [Online]. Available: https://www.decodingdiscontinuity.com/p/turboquant-memory-stock-sell-off-panic-paper-google. [Accessed: Mar. 2026].
[4] TechPowerUp, ‘DRAM Manufacturer Stock Prices Dip Over Google TurboQuant Announcement,’ March 27, 2026. [Online]. Available: https://www.techpowerup.com/347798/dram-manufacturer-stock-prices-dip-over-google-turboquant-announcement. [Accessed: Mar. 2026].

